

Google (GOOG) Goes Down: Search, YouTube And Gmail Crash, Web Traffic Down 40 Percent

Google (NASDAQ:GOOG) faced a brief but serious outage on Friday, with all services -- including YouTube, Gmail and the company’s search engine -- down for about two minutes. The services crashed at 4:37 p.m. PDT for one to five minutes, and all operations were fully restored by 4:48 p.m.
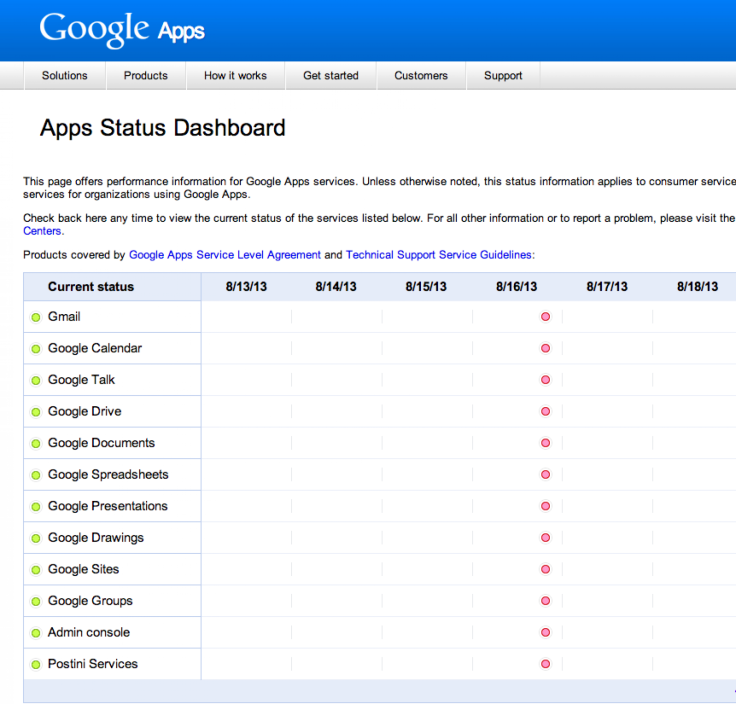
The Google Apps Dashboard showed that every Google service simultaneously went down, causing worldwide Web traffic to drop about 40 percent, according to GoSquared, an Internet analytics company. When the Google services were restored, Internet traffic briefly spiked afterward.
Google would not comment on what caused the issue, but a representative referred to the Apps Status Report, which said "between 15:51 and 15:52 PDT, 50 percent to 70 percent of requests to Google received errors; service was mostly restored one minute later, and entirely restored after 4 minutes." Google’s outage was likely due to an issue with the Internet service provider (ISP) at one or more of its data centers, according to Martin Drury, network expert and senior systems engineer at Micro Strategies Inc.
Outages are bound to happen occasionally, but for a company with services as wide-ranging as Google's, downtime is costly, with one report stating Google likely lost about $500,000 in that brief period. According to one network analytics firm, 60 percent of the world's Web traffic interacts with Google's servers throughout the day. Drury said it was likely a “utility-related outage” -- a network cable was destroyed that connected one or more of Google's data centers -- as the failure of a single server would not cause such a widespread problem.
“If a server fails, another server will cover it, but everything is reliant on the network,” Drury said. “Outages can occur, and when companies don’t test redundancy and they trust the ISP, outages like that can happen.”
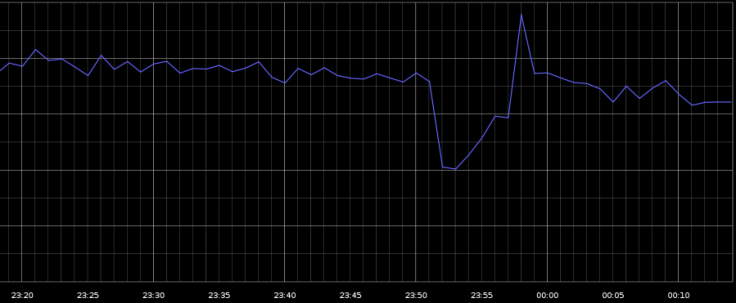
Drury said that most outages are caused by the ISPs themselves accidentally cutting a line when digging to lay down new fiberoptic lines or make repairs.
“Companies like Google tend to get comfortable, knowing that they designed their system so that there's no single point of failure. But the world, the network, and the data centers aren’t static,” Drury said. “Since these things are so dynamic, you’ve got to have a plan in place to test redundancies. In this case, whoever was in charge of network redundancy either didn’t implement it correctly, or didn’t test the network failsafe to make sure it was properly functioning.”
© Copyright IBTimes 2024. All rights reserved.
-

Taiwan Hit By Dozens Of Strong Aftershocks From Deadly Quake
-

Gaza Health System 'Completely Obliterated': UN Expert
-

In Ecuadoran Amazon, Butterflies Provide A Gauge Of Climate Change
-

50 Years On, Vintage Vehicles To Reenact Portugal's Carnation Revolution
-

Conflicts Push Military Spending To 'All-time High': Report
-

'Thank You, America:' Zelensky And Netanyahu Applaud House Passage Of Foreign Aid Package
-

Women Journalists Bear The Brunt Of Cyberbullying
-

US Aid Shows Ukraine Will Not Be 'Second Afghanistan': Zelensky
-

Elon Musk's X Fights Australian Watchdog Over Church Stabbing Posts
-

Ukraine, Israel, TikTok: The Massive Aid Package Before US Congress









